
Introduction
Voilà bien longtemps que je n’ai plus écrit d’article pour Cuk. Ceux qui suivent un peu la vie du site et le forum sauront qu’après avoir terminé ma thèse j’ai commencé à travailler pour une société suisse, basée à Genève, et répondant au doux nom d’Acqiris .
Cette société est spécialisée dans la numérisation de données à très haute vitesse. En fait, le succès de cette société était tel que nous avons été rachetés au début de l’année par le géant américain Agilent, société issue du “spin-off” de HP il y a six ans (oui, oui, HP, comme dans Hewlett Packard).
Mais le but de cet article n’est pas de vous raconter ma vie, qui est somme toute assez insignifiante, mais c’est bien de vous parler de la numérisation de données. Car, tel M. Jourdain, vous utilisez la numérisation de données tous les jours, probablement sans le savoir.
Qu’est-ce que la numérisation ?
De nos jours, l’informatique est omniprésente et avec elle, le numérique. Je crois qu’il est difficile de passer une journée sans entendre ou lire ce mot: numérique.
En fait, la définition est assez simple, une information numérique est une information codée grâce à des 1 et des 0. L’information numérique est aussi appelée “digitale” (bien que ce soit un anglicisme).
Au numérique, on oppose souvent l’analogique. L’analogique c’est la représentation d’un signal ou d’une information par une grandeur physique continue, telle que la position, la tension, etc.
Je sais ce n’est pas très très clair, mais un exemple va clarifier tout ça.
Un exemple: le son
Le son est un monde fascinant et de plus très fréquemment utilisé sur nos ordinateurs. Cela en fait donc un parfait exemple.
Si vous vous souvenez bien, j’avais écrit un article sur le son il y a bien longtemps de cela.
J’expliquais dans cet article ce qu’était un son, ou quelle était sa représentation physique. Brièvement, un son est une onde de pression. C’est donc, si je me place à un endroit précis, une variation de la pression locale. Ces variations de pression arrivent dans votre oreille et font vibrer votre membrane.
Un son basique pourra donc être représenté par une courbe sinusoïdale indiquant la variation de pression en un endroit donné, en fonction du temps.
Comment allons-nous transformer cette information physique (variation de pression) en une information utilisable par un ordinateur ?
Tout le monde le sait, l’essence même d’un ordinateur c’est l’électricité. La première étape sera donc de transformer cette information “pression en fonction du temps” en une information “tension en fonction du temps”. Rien de plus facile, par exemple avec un piézo.
Pour l’instant, nous avons toujours affaire à un signal analogique, aucune perte d’information n’est survenue lors de la conversion pression->tension (pour autant que le système de conversion soit efficace) et nous avons toujours une grandeur physique continue: la tension.
C’est maintenant qu’intervient le processus de numérisation de l’information. Celui-ce se fera à l’aide d’un ADC (Analog-to-digital-converter, convertisseur analogique-numérique). Toutefois, si le monde réel est un monde continu, le monde informatique est quant à lui un monde discret ou quantifié.
Je m’explique.
Si je dois vous donner la position d’un objet posé sur une feuille de papier, par rapport à un coin de ladite feuille, je pourrai vous la donner avec autant de précision que vous le voulez (en admettant que j’ai les moyens de mesure adéquats), genre X=11,3456742 cm et Y = 19,23789 cm. Rien ne m’empêcherait de vous donner plus de décimales et donc plus de précision. Cette grandeur physique (la longueur, ou la position) est une grandeur continue.
Si maintenant, je dois vous donner la position de votre pointeur de souris sur l’écran de votre ordinateur, je ne peux être précis qu’au pixel près. Avec une résolution de 1024×768, la position X ne pourra prendre qu’une valeur entière située entre 1 et 1024, et la valeur Y entre 1 et 768. C’est une grandeur discrète, ou quantifiée.
Autre exemple: la couleur. Dans le monde réel, il y a une infinité de nuances de couleurs différentes, notre oeil est la seule limitation à la perception de ces différences. Sur un ordinateur, le nombre de couleurs possible est déterminé par la profondeur choisie par l’utilisateur. Par exemple, avec une profondeur de 8 bit, on a 256 couleurs (ou nuances) à disposition (28 = 256), avec une profondeur de 24 bit, on en a 16 millions (224 = 16777216).
La numérisation des données va donc obligatoirement impliquer une discrétisation de l’information et donc une détérioration de cette information.
Tout comme la position d’un objet nécessite deux variables (X et Y), la numérisation d’un signal temporelle nécessite la discrétisation de deux grandeurs: le temps (X) et la tension (Y).
Comme je l’ai déjà mentionné, la discrétisation doit se faire sur deux variables: le temps et la tension.
Pour le temps, c’est assez simple, il suffit de décider d’une fréquence d’échantillonnage. C’est-à-dire, répondre à la question “Je prends une mesure tous les combien de temps ?”. Plus la fréquence d’échantillonnage est grande, plus l’information sera précise, mais plus j’aurai besoin de place pour la stocker. Évidemment, la fréquence d’échantillonnage maximum qu’il est possible d’atteindre dépendra du matériel utilisé. Je reviendrai là-dessus.
Ansi, la discrétisation temporelle d’un son représenté dans le monde “réel” par une sinusoïde donnera par exemple ceci:
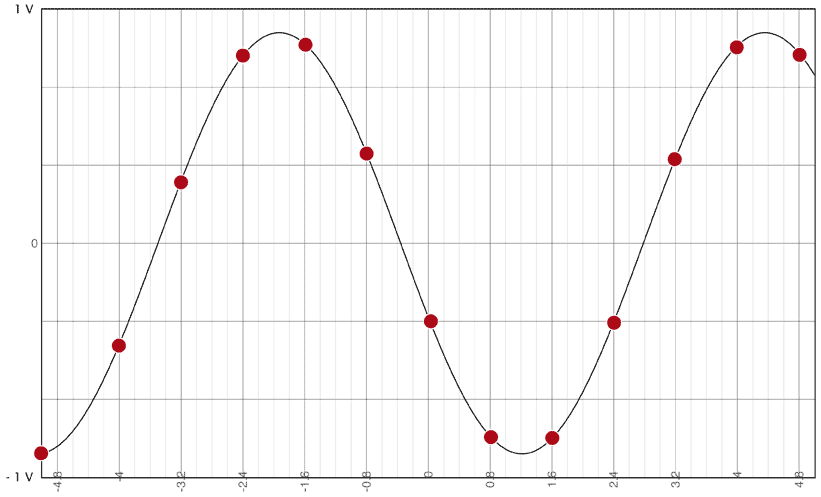
Cette discrétisation est forcément nécessaire. Dans l’exemple ci-dessus, la quantité d’information à stocker sera assez faible, la courbe est discrétisée à l’aide de 13 points. Si je voulais plus de précision, il me faudrait plus de points et j’aurais donc une plus grande quantité d’information à stocker.
Pour la tension, c’est comme pour les couleurs, c’est la profondeur, ou résolution qui va décider de la précision de la mesure. Comme pour les couleurs, celle-ci s’exprime en “bits”.
Prenons un exemple concret. Admettons pour simplifier que j’ai une résolution de 2 bits. J’aurai donc 22 = 4 niveaux à disposition et donc 4 valeurs possible. Si j’ai une échelle verticale qui va de –1 V à +1 V, j’aurai donc 3 cases (entre les 4 niveaux) de 333.33 mV (1-(–1)/(22-1)):
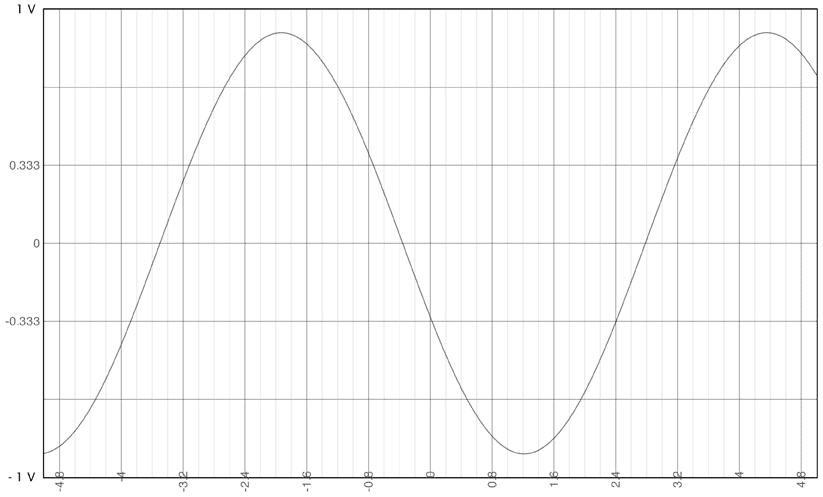
Les valeurs possible seront donc -1 V, – 333.33 mV, +333.33mV et 1 V. Ma résolution sera donc de 333.33 mV. Mon dispositif de conversion ne sera pas en mesure de faire la différence entre une mesure à 400 mV et une mesure à 500 mV, toutes les deux seront “vues” par le numériseur comme une mesure à 333.33 mV.
La sinusoïde que je montrais plus haut sera donc numérisée de la manière suivante sur l’ordinateur:
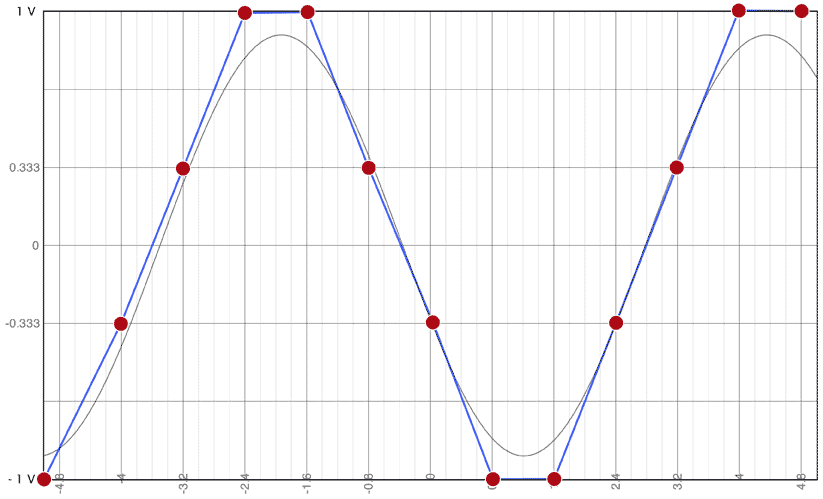
Similairement, une résolution de 8 bit signifie que l’on a 28 = 256, niveaux à disposition. Je peux donc placer ma mesure dans l’une des 255 “cases” que j’ai à disposition, et j’aurai une résolution de 7.84 mV (1-(-1)/(256-1)).
La conséquence de cela, c’est que si chaque point est “codé” sur 8 bit, il faudra stocker 8 bit = 1 octet par point.
Évidemment, tout cela c’est de la théorie et dans la pratique, il y a beaucoup de facteurs qui interviennent et qui sont susceptibles de dégrader la mesure. Mais je vous épargnerai ça.
Et sur mon Mac ?
Evidemment, si je vous raconte tout ça, c’est aussi parce qu’il y a un rapport avec le Mac. La plupart des Macs récents ont un micro intégré qui permet de numériser du son. La documentation technique d’Apple nous indique que la numérisation peut se faire avec une résolution de 16, 20 ou 24 bits et que la fréquence d’échantillonnage peut prendre les valeurs 44.1, 48 et 96 kHz (donc 44100, 48000 ou 96000 échantillons par seconde).
De même, si vous regardez la fenêtre d’exportation d’un son dans Quicktime, vous verrez ceci:
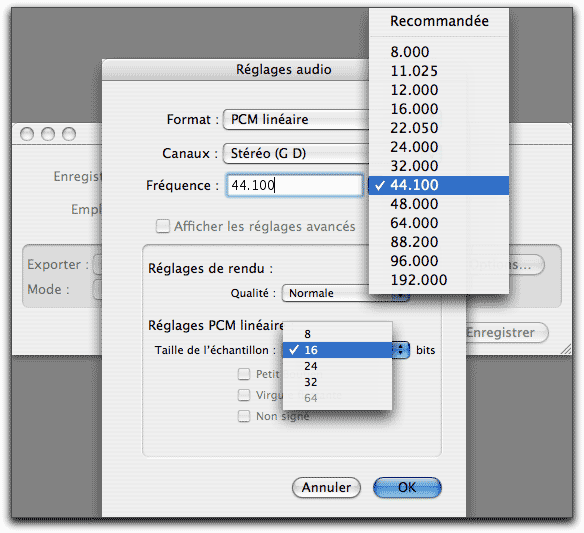
Vous retrouvez là tout ce que je viens de vous dire, la résolution ainsi que la fréquence d’échantillonnage.
La fréquence d’échantillonnage est un paramètre crucial lors de la numérisation des données. En effet, le théorème de Shannon-Nyquist indique que:
la fréquence d’échantillonnage d’un signal doit être égale ou supérieure au double de la fréquence maximale contenue dans ce signal.
Sans aller dans la démonstration de ce théorème, ce qu’il faut en tirer c’est que si le signal que vous désirez numériser contient des hautes fréquences et que votre fréquence d’échantillonnage est trop faible, ces hautes fréquences seront perdues.
Vous êtes-vous jamais demandé d’où venait cette fréquence “magique” de 44.1 kHz qui est utilisée pour numériser des sons à destination des CDs par exemple ?
L’oreille humaine est capable d’entendre des sons jusqu’à une fréquence de 16 à 20 kHz. Selon le théorème de Shannon-Nyquist, il faut donc échantillonner à une fréquence au moins double de cette valeur. L’industrie a donc décidé de fixer 44.1 kHz comme fréquence d’échantillonnage pour les signaux sonores.
Et pour finir ?
Maintenant que la numérisation de données n’a plus de secrets pour vous, vous pouvez vous demander ce qui fait que cette ex-petite société genevoise dans laquelle je travaille est si différente des autres. Qu’est-ce qui fait que ce que nous faisons est différent de ce que vous avez tous dans votre ordinateur ?
Évidemment, tout est dans les performances. Là où une carte son est capable d’échantillonner à 44.1 kHz, 48 kHz, voir 192 kHz, les numériseurs que nous faisons échantillonnent jusqu’à 8 GHz (près de 50’000 fois plus vite), ce qui nous permet de numériser des signaux de très hautes fréquences (de l’ordre du GHz).
J’espère que cette rapide introduction à la numérisation de données vous aura permis de comprendre (pour autant que cela était nécessaire) quelques-uns de ces chiffres et termes que vous croisez souvent sur votre ordinateur comme 44.1 kHz, 16 bits, 24 bits, par exemple. Si vous avez des questions, les commentaires sont évidemment ouverts.
Bonus
Vous voulez prédire la taille qu’un fichier son occupera sur votre disque dur ? Alors, voici un petit exercice de calcul. Si vous prenez une chanson de 3 minutes (180 s) et que vous l’exportez au format AIFF (non compressé, donc) avec un échantillonnage de 44.1 kHz et une résolution de 8 bit, vous obtiendrez un fichier d’un peu plus de 7.5 Mo (44100 Hz * 180 s * 1 octet).
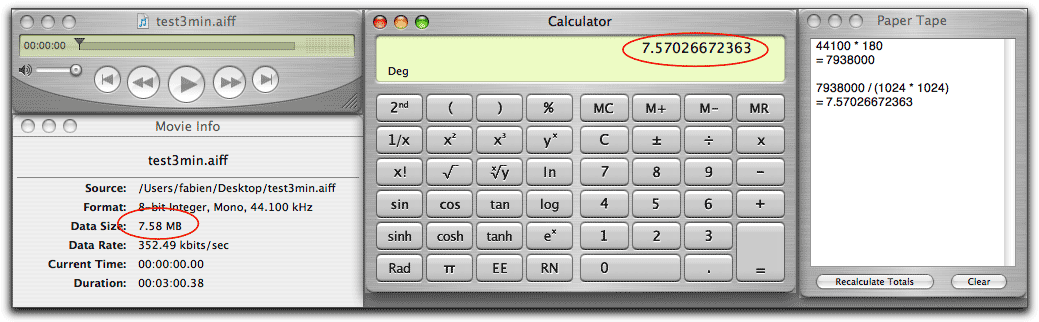
De même, si vous utilisez une résolution de 16 bit (2 octets par mesure), le fichier prendra environ 15 Mo.
, le 11.06.2007 à 00:18
Fabien, le retour ! Et comme d’habitude, un article passionnant !
Je suis aussi confronté en ce moment au fait qu’un ordi discrétise les données réelles… D’où la perte obligatoire de précision, qu’on appelle en math erreur d’arrondi, et dont il faut évaluer les conséquences sur nos méthodes et algorithmes : pas une mince affaire !
, le 11.06.2007 à 00:57
Petite précision quant à cette fréquence d’échantillonnage étonnante de 44.1 kHz. 44.1 ? Pourquoi pas simplement 40 kHz, pour pouvoir enregistrer des sons jusqu’à 20 kHz (40 / 2 selon Shannon) ? Et pourquoi pas 44 kHz tout rond ?
En fait, il ne suffit pas de numériser au double de la fréquence que l’on souhaite enregistrer. Il faut tout d’abord filtrer afin d’éliminer, avant numérisation, les fréquences que l’on ne va pas enregistrer, sans quoi on assistera à d’étranges phénoménes nommés aliasing (ou repliement de spectre). Vous aurez surement déjà été confronté à cet phénomène en diminuant la taille d’une photographie dans un logiciel de retouche simple : ces fameux effects de moiré sur des éléments répétitifs de l’image – murs de briques ou toits de tuiles, barrières en lattes, etc.
Il faut donc filtrer. C’est d’autant plus important avec le son que l’oreille est véritablement très sensible à ce phénomène, beaucoup plus que les yeux qui corrigent beaucoup de choses. La “résolution” des yeux est en effet bien moindre que la résolution de l’oreille. Saviez-vous que nos yeux et nos oreilles sont numériques (échantillonnent) ? Mais je disgresse. Filtrer il faut, donc. Et comme les filtrages ne sont pas absolument parfaits, avec 19.99 kHz parfaitement transmis et 20.01 kHz parfaitement éliminé, il a fallu prendre une petite marge pour que l’efficacité du filtre soit suffisante. Ce filtre coupe pour ainsi dire pas à 20 kHz, un peu à 21 kHz, pas mal à 22 kHz, très bien à 23 kHz. La fréquence de 22.05 kHz correspond précisément à une atténuation considérée comme suffisante. D’ou, selon Shannon, cette fréquence de 22.05×2 = 44.1 kHz.
Et quid des fréquences de 48 kHz, 96 kHz, etc. ? Les raisons du 44.1 kHz étaient mathématiques et pratiques. C’est la plus petite fréquence acceptable pour qu’un son destiné à une oreille humaine soit restitué correctement, pour la plus longue durée possible sur un CD. 48 kHz facilite le filtrage, on a plus de marge, et c’est un chiffre rond. Les autres fréquences sont simplement des multiples de 48 kHz et permettent simplement d’améliorer la finesse des enregistrements en ajoutant une octave (et oui, seulement une octave) à chaque doublement, et d’améliorer encore le filtrage initial.
La question du nombre de bits par échantillon est toute différente. Il s’agit en réalité d’une seconde numérisation, tout à fait indépendante de la première.
Un orchestre qui joue peut jouer très doucement ou au contraire très fort. Les variations peuvent atteindre, pour une meme oeuvre !, près de 80 dB. Entre 40 dB, le bruissement des feuilles loin de toute civilisation à 120 dB, un marteau piqueur dans la rue, il y a un monde. Un monde qui peut etre restitué avec 16 bits par échantillon, correspondant à une amplitude de 96 dB. Et voilà.
, le 11.06.2007 à 06:27
Immensément content de te retrouver parmi nous!
Merci.
, le 11.06.2007 à 08:04
Salut, Fabien! Quel plaisir de te retrouver!
Si tu persistes à chercher des places dans l’industrie privée, l’enseignement y perdra énormément. Tu prives des milliers d’élèves de cours passionnants. Je m’en étais déjà rendu compte à ta soutenance de thèse. T’es fait pour ça, mon vieux! T’y peux rien!
Milsabor!
, le 11.06.2007 à 08:57
Content de te lire à nouveau Fabien! Avec un article très intéressant, comme d’habitude =)
Si ce n’est pas trop indiscret ni trop complexe, quel est ton rôle dans cette entreprise?
, le 11.06.2007 à 10:00
Ne pas oublier de multiplier par 2 le résultat indiqué à la rubrique Bonus pour un fichier stéréo, ce qui donne un ratio d’environ 10 Mo/minute pour un fichier audio stéréo rippé à partir d’un CD et sans compression. Petite question : la plupart des fabricants de cartes son propose des modèles échantillonnant jusquà 192 KHz en 24 bit. Quel en est l’intérêt si l’on considère qu’une fq de 44.1 KHz sous 16 bit est suffisante pour restituer fidèlement un enregistrement, même sur le plan dynamique (à part vendre des disques durs + gros et rendre les machines + rapidement obsolètes) ? A bientôt
, le 11.06.2007 à 10:02
Merci pour cet article Fabien ça me rappelle mes cours d’électronique, que de bons souvenirs !
Tu devrais écouter Caplan et me donner les coordonnées de ton ton RH :)
, le 11.06.2007 à 10:55
24 bits tout d’abord. 24 bits correspondent à une dynamique de 144 dB. L’idée n’est pas de pouvoir restituer le bruit de l’herbe qui pousse et le crash d’un 747 sur le pas de votre porte, mais d’augmenter le rapport signal / bruit.
Chaque traitement (numérique) sur le son est en fait une série plus ou moins complexe d’opérations mathématiques. Chaque opération va introduire une petite erreur de calcul du fait du nombre de bits déterminés. Si on utilisait une précision infinie le problème n’existerait pas, mais ce n’est pas le cas. Il faut donc faire des arrondis pour coller aux 24 bits (ou 16) de chaque échantillon. Souvent, les processeurs sonores travaillent sur des échantillons en virgule fixe ou flottante, sur 32 bits par échantillon, dans le but de minimiser les erreurs d’arrondi. Et chaque arrondi ajoute du bruit, qui à force devient audible. Un peu comme une succession de compressions JPEG : on fini par dégrader l’image. Mais là encore, l’oeil est plus tolérant que l’oreille. Un organe magnifique que l’oreille !
On admet communément que le CD a un rapport signal / bruit de 96 dB. C’est vrai et c’est faux. Ce serait vrai si la musique était toujours à plein volume, mais ce n’est en réalité pratiquement jamais le cas. Au mieux, on utilise entre 84 et 90 dB de dynamique “moyenne”, soit donc un rapport signal bruit de 84 à 90 dB. L’oreille à une dynamique de 60 dB environ à un moment donné. La différence entre le son le plus fort et le son le plus faible perçus en meme temps sera donc de 60 dB. Un rapport signal bruit plus important signifie que l’on entrendra (théoriquement) pas le bruit.
Seulement voilà, lorsque l’orchestre joue doucement, seuls 30 ou 40 dB de dynamique sont utilisés. Et le bruit devient très audible dans ce cas. En 24 bits, on ajoute 48 dB de dynamique, donc on rejette le bruit au delà de ces 60 dB audibles meme lorsque l’orchestre joue une berceuse, tout en gardant une marge pour du filtrage supplémentaire (qui ajoute du bruit).
Quant à la fréquence d’échantillonnage, comme je le disais dans un précédent commentaire, chaque doublement ajoute une octave et seulement une octave. Entre 20 et 20’000 Hz, il y a 10 octaves. Ajouter une ou deux octaves n’est pas si énorme que ça somme toute. Il ne faut pas penser fréquence d’échantillonnage et taille de fichiers, ça augmente très vite et c’est impressionnant. Il faut penser à ce que l’oreille entend. Une octave, c’est peu, + 10%.
Pourquoi ajouter une octave que l’on entend de toute manière pas ? Et bien en fait, si, on l’entend. On n’entend pas directement une fréquence de 30 kHz évidemment. Mais beaucoup d’instruments produisent de telles fréquences et lorsqu’elles ne sont pas présentes soit parce que les hauts-parleurs ne sont pas capables de les restituer soit parce que l’enregistrement numérique les a éliminées, la forme de l’onde sonore est différente. Subtilement différente, mais néanmoins différente. Et il se trouve que l’oreille perçoit cette différence de forme d’onde, très faiblement et très subtilement.
Et encore une fois, on laisse plus de marge de manoeuvre aux traitements sonores pour altérer le moins possible le son. Ici il n’est plus question de bruit numérique, mais de forme d’onde et de phase.
Bref, tout ça pour dire que le CD offre le minimum de qualité indispensable pour restituer la musique fidèlement. Mais selon les standards actuels en aucun cas on peut qualifier un CD de haute fidélité.
La compression du son est une affaire bigrement complexe. Les meilleurs algorithmes utilisent tous des phénomènes psychoacoustiques pour éliminer un maximum de fréquences sans que l’écoute ne soit trop altérée. C’est fascinant croyez-moi. La différence entre ce que donnent un original 24 bits 192 kHz et un mp3 128 kbits/s est tellement énorme et pourtant si semblable à l’oreille…
, le 11.06.2007 à 14:44
Très intéressant, merci.
Tu pourrais nous donner des exemples concrets d’utilisation de ces appareils?
, le 11.06.2007 à 15:32
Bonjour à tous et merci mille fois pour vos commentaires.
FT’e, merci pour ces précision et informations extrêmement utiles et intéressantes.
Caplan, le jour où la HEP aura un quelconque semblant de logique, d’intérêt et d’intelligence, on pourra reparler de mon avenir dans l’enseignement.
6ix, je suis “Technical Marketing Engineer” et “Program Manager”. Donc en gros, je fais de la relation clientèle au niveau technique et je gère des grands programmes pour de gros clients.
clapton22, oui, en mode stéréo on doit considérer que l’on numérise deux informations différentes. Pour le reste des questions, je pense que FT’e y a brillamment répondu.
Puzzo, merci pour cette question ;-) Nos produits sont utilisé dans moultes applications différentes. Notre site internet en présente quelques-unes: http://www.acqiris.com/applications.html
Par exemple:
mesure du temps de demi-vie de rayons béta au CERN
observations de rayons gamma venus de l’espace
imagerie médical avec de la tomographie à émission de positrons
spectrometrie de masse temps de vol pour la biotechnologie
systèmes radars
Ce ne sont que quelques exemples. Parmis nos clients figurent Intel, Fujitsu, Seagate, EADS, Motorola, etc.
Les applications sont véritablement multiples.
, le 11.06.2007 à 15:54
Intéressant!
Fabien n’en fait pas mention il me semble mais la compagnie dans laquelle il travaille faisait partie de Hewlett-Packard (oui, les PC) et elle fût séparée en 1999 de son nom… (mais c’est pourtant Agilent qui ressemble le plus à ce que HP faisait dès sa création dans les années 40).
Globalement, une bonne partie des revenus proviennent du secteur aerospace/defense…
T
, le 11.06.2007 à 16:07
Salut T.
Si, si, j’en parle dans l’introduction (deuxième paragraphe).
Et effectivement, HP faisait beaucoup plus d’appareils de mesures que de PC.
, le 11.06.2007 à 16:24
Ah… désolé, ça m’apprendra à lire de travers…
T
, le 11.06.2007 à 18:22
Content de te lire à nouveau Fabien! Et cet article est super intéressant. J’ai lu pas mal de trucs sur les fréquences d’échantillonage et tout ces trucs (surtout pour la musique) mais ton article fait une très bonne synthèse.
, le 11.06.2007 à 18:43
Merci pour ce bel article. Tu as expliqué pourquoi échantillonner à 44.1 kHz, moi je vais expliquer pourquoi on numérise sur 2 pistes, parce qu’on a 2 oreilles. Ce que je suis intelligent :•)
Je n’ai pas une bonne oreille, mais de lire cet article me fait me poser la question suivante : Aurait-ce été une alternative crédible de numériser sur 3 pistes : 2 pour les sons normaux à aigus en stéréo, et un pour les graves en mono ? Je pense à ça vu que souvent les chaînes HiFi ont 2 enceintes et un gros Woofer.
, le 11.06.2007 à 20:22
Hello,
“Les raisons du 44.1 kHz étaient ” sont historique, c’est lié au fait que lors des premières numérisations audio – les techniciens utilisaint des magnétoscopes vidéo.
La fréquence d’échantillonnage de 44,1 kHz est héritée d’une méthode de conversion numérique d’un signal audio en signal vidéo pour un enregistrement sur cassette vidéo qui était le seul support offrant une bande passante suffisante pour enregistrer la quantité de données nécessaire à un enregistrement audionumérique PCM Adaptor (en). Cette technologie peut stocker 6 échantillons (3 par canal en stéréo) par ligne horizontale. Un signal vidéo NTSC possède 245 lignes utilisables par trame et 59.94 champs par seconde qui fonctionne à 44 056 échantillons par seconde. De même, un signal vidéo PAL ou SECAM possède 294 lignes et 50 champs qui permet aussi de délivrer 44 100 échantillons par seconde. Ce système pouvait aussi stocker des échantillons de 14 bits avec des corrections d’erreur ou des échantillons de 16 bits sans correction d’erreur. Il y eu donc un long débat entre Philips et Sony concernant la fréquence et la résolution de l’échantillonnage. Philips voulant utiliser le 44 100 Hz utilisé en Europe et une résolution de 14 bits ayant déjà développé des CNA 14 bits et Sony voulant imposer le 44 056 Hz utilisé au Japon et Etats-Unis et une résolution de 16 bits.
source : http://fr.wikipedia.org/wiki/Disque_compact#Histoire
, le 12.06.2007 à 08:28
Superbe article et superbes commentaires (pas très gentil, Fabien ton jugement sur la HEP !).
Pour Tom25, cela fait un moment qu’on peut séparer les canaux. Il y a eu par exemple le Dolby Prologic qui offrait une voie gauche, une centre, une droite et le surround. Aujourd’hui, le Dolby digital (entre autre) permet toute une série de séparations possible dont la plus utilisée est le 5.1 (gauche-centre-droite-arrière gauche-arrière-droite et surround). Le problème est que ces signaux sont compressés (un peu comme du MP3) et on est loin de la qualité du 96kHz en 32bits !
, le 12.06.2007 à 08:40
Ah ben je ne savais même pas que c’était ça le Dolby, justement je me demandais… Mais un CD ne peut pas être Dolby alors ? Si le standard CD c’est 2 pistes à 44.1 kHz etc. Faudra que je regarde mes CDs, mais il me semble qu’il y a parfois écrit Dolby derrière.
, le 12.06.2007 à 09:07
Mais tellement vrai Roger! Moi, cette boîte me rend physiquement malade chaque fois que j’y mets les pieds. Vraiment, j’entre, et j’ai mal au bide.
, le 12.06.2007 à 14:41
Désolé Roger, mais j’ai laissé tomber l’idée de me lancer dans l’enseignement uniquement à cause de la HEP. Et pourtant j’étais motivé !
, le 12.06.2007 à 15:09
Théoriquement, un CD peut être encodé en Dolby Surround ou Prologic: le principe de ces 2 Dolby est de combiner le son pour 3 canaux (Dolby Surround) ou 4 canaux (Dolby Prologic) sur 2 pistes (stéréo donc). Si on dispose d’un équipement stéréo, les pistes peuvent être lues normalement et si on dispose d’un décodeur, il est capable de séparer les voies supplémentaires et les envoyer sur les “baffles” dédiés. Ces 2 procédés sont en fait analogiques.
À ne pas confondre avec les Dolby Digital et autres THX où là chaque canal dispose d’une piste qui lui est propre.
, le 13.06.2007 à 20:34
Je plussoye complètement: magnifique article et non moins captivants commentaires, c’est beau la pédagogie!
z (l’échantillonage, c’est pas pour ton âge, je répêêête: l’échantillonage, c’est pas pour ton âge)