
ou
la terrible vengeance du come-back du return (et il n'est pas content du tout)
La beauté des liens many-to-many, la souplesse des identifiants.
Nous allons aujourd'hui rendre justice à la ressource la plus insoupçonnée de FileMaker, qui est aussi la plus unanimement méprisée et mésestimée: la touche return.

Figure 1: le retour chariot dans toute sa splendeur discrète.
Que ceux qui pensent que je n'ai plus toute ma tête se gaussent. Maintenant. Qu'ils profitent. Parce que dans quelques minutes, ils feront moins les fiers. Leurs petits camarades qui auront suivi, eux, auront une toute nouvelle perception de la structure relationnelle de FileMaker. Oui, même François.
Mais retournons-nous d'abord quelques instants sur le chemin parcouru.
Genèse
Au début était le Fichier. Il était Grand, mais il était vide. Dieu créa alors la rubrique, et donna le mot de passe administrateur à l'homme. L'homme prit le fichier, et y mit des choses. Plein de choses. Toutes ses choses, dans autant de rubriques qu'il pouvait en rêver. Tellement de choses, qu'au bout d'un moment, il ne se retrouva plus lui-même dans son Fichier. Dieu, qui était bon, vit l'homme souffrir, et lui offrit l'identifiant, ou Clé Primaire (abrégé pk pour Primary Key, car Dieu ne parlait qu'anglais à cette époque). L'homme respira mieux. Il trouva à nouveau toutes ses choses, car il put les coder, les référencer. Il put commencer à en oublier certaines, car il était sûr de pouvoir mettre la main dessus au moment voulu. Dieu, pour le récompenser de son excellent travail, permit alors à l'homme d'utiliser les multivaluées. L'homme y mit encore plus de choses, il put les regrouper dans chaque fiche du Grand Fichier, au lieu de les mettre sur plusieurs fiches comme avant. C'était mieux.
Mais Dieu trouva que le Fichier était triste, car il était unique. Il prit une fiche (l'avant-dernière) du Grand Fichier, et en fit un clone. Il trouva cela bon, et but un peu d'eau. Pour que les deux Fichiers ne soient jamais plus seuls, Dieu créa le lien. Les fichiers devinrent relationnels. Ils furent heureux, car l'homme les liait tant et plus.
Puis les fichiers devinrent complexes. Les relations se multiplièrent, s'entremêlèrent. Les choses n'étaient plus aussi simples qu'au début. Les multivaluées étaient indispensables, mais elles ne permettaient de lier les Grands Fichiers que dans un sens. L'homme n'arrivait plus à mettre toutes ces choses en ordre dans l'Ordinateur. Dieu était triste de ce pitoyable spectacle. Il demanda à l'homme, qui souffrait plus encore qu'avant les multivaluées, ce qu'il pourrait faire pour atténuer ses souffrances.
L'homme dit: "Donne-moi les liens many-to-many."
Et Dieu créa le Return.
Revenons à nos moutons
Nous avons vu dans le premier volet de ce triptyque que l'index était la manière la plus puissante de permettre à un indice d'exprimer sa quintessence, et permettre de révéler à tous les coups la fiche recherchée. Dans le second volet, nous avons butiné de fiche en fiche, dans tous les sens.
Mais quel est exactement le secret que nous avons exploité? C'est déjà le return, ni plus ni moins, mais nous ne l'avons utilisé qu'à la moitié de sa puissance, du côté de l'index.
À ma droite: la destination du lien, dans le fichier lié, le fichier de référence
En effet, l'indice (source de notre lien) pointait vers un index, qui, comme son nom l'indique, contient toutes les déclinaisons pertinentes de plusieurs mots de quelques champs soigneusement choisis. Et entre chacune de ces déclinaisons, il y a un return. Ça n'a l'air de rien, mais c'est le fin fond du mécanisme. Voilà pour le bout du lien. C'est le côté droit d'une relation 1-N ou one-to-many.
Certains feront judicieusement observer (comme nous le disions dans notre premier volet) que les rubriques comprenant plusieurs valeurs séparées par des returns ne sont pas la seule façon de tirer des liens one-to-many: une multivaluée aussi fonctionne très bien à droite du lien. C'est vrai, mais...
- il est beaucoup plus difficile de contrôler séparément les calculs effectués dans chacune des cases d'une multivaluée
- et surtout, il est obligatoire de prévoir à l'avance la dimension des multivaluées, leur profondeur.
Notre index est donc basé sur une rubrique contenant autant de returns que nécessaire, la liberté de calcul étant dans ce cas totale.
À ma gauche: la source du lien, son attache
Lorsqu'on fait ses armes avec les multivaluées, arrive un jour où l'on découvre avec vertige que le lien tiré est en réalité multifibre (un peu comme les cordages tressés de petites fibres sont plus solides que les filins massifs de même diamètre). Toutes les valeurs de la multivaluée, quelle que soit leur profondeur, permettent au lien de jouer son rôle.
Tout à son enthousiasme, on se dit alors, par analogie, que cela doit fonctionner aussi à gauche du lien. Et de tirer un lien entre deux rubriques multivaluées. La stupéfaction est encore plus grande: ça ne marche pas! Le lien, résolument, ne part que de la première valeur d'une multivaluée. C'est assez déroutant (il faudra d'ailleurs que le grand FaiseursDeFichiers en personne s'en explique un jour...), la déception est totale, la résignation vous gagne.
Une fraute de fappe divine
Depuis lors, vous vivez paisiblement, mettant des valeurs dans vos champs, tirant des liens 1-N, apprivoisant les multivaluées, découvrant le relationnel à petites sirupées.
Vous pestez, de temps en temps, comme tout le monde, contre le fait que dans FileMaker la touche return est dénaturée:
- Elle n'est pas interceptable par un script: on aimerait tellement, tellement qu'un bouton visible dans un modèle puisse être cliquable rien qu'en appuyant sur return.
- On est presque étonné que le return soit utilisable lorsqu'on est en mode Recherche.
- Combien de fois êtes-vous tombé sur un champ qui contient un return non voulu, fichant en l'air un calcul? Vous n'avez naturellement pas songé à contrôler systématiquement l'existence de retours chariot indésirables pour les bannir de tous les champs où vous ne voulez strictement qu'une ligne de données.
Bref, imperceptiblement, vous intégrez le fait que FileMaker gère bizarrement la touche return, qui si souvent signifie "Validation", "OK" ou "Ligne suivante" dans tous les autres programmes habituels de notre monde informatique. Hérité de la machine à écrire, cette touche est souvent synonyme d'action. La touche return a à peu près autant de force que le bouton de la souris, Sa Majesté le Clic.
Mais FileMaker est une application différente (c'est ce qui déroute François): elle traite le return délicatement, laissant le Clic seul responsable des actions. Toutes les touches du clavier ont leur utilité, le return comme toutes les autres, l'interface étant guidée exclusivement par la souris.
Voyons comment nous pouvons tirer un énorme profit du return, qui permet de rentrer un caractère quasiment comme n'importe quel autre, mais avec une nuance de taille: le return est un séparateur. Bon sang, ce détail aurait pourtant dû nous mettre le processeur à l'oreille...
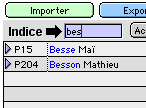
Figure 2: on rentre un indice. On trouve les "bes".
Vous croyez peut-être que nous vous avons présenté la Recherche rapide et la Navigation dans le seul but de passer aisément d'une fiche à une autre, par le truchement d'un indice, comme le montre la figure 2? Touchante naïveté!
Nous avons fait tout cela (nous l'avons précisé dès le début) car nous avons horreur du mode Recherche ó tout comme la Nature a horreur du vide ó car il est vil et dangereux (et François sera le premier d'accord). Nous exigeons de dès lors trouver des fiches tout en restant en permanence en mode Utilisation. En effet, en mode Recherche, cette pauvre touche return est enchaînée à la seule action "exécuter la requête", un peu comme si la main ne servait qu'à lancer des bâtons à son chien en lui disant "Va chercher!" La main sert de plus nobles desseins. La touche Return aussi.
En faisant l'effort de l'index, nous atteignons ce but. Sans le remarquer, nous venons de libérer le return.

Figure 3: laissez-vous illuminer, appuyez sur la touche proscrite.
Comme le montre la figure 3, nous devons donc nous laisser illuminer, et commettre l'irrévocable: mettre un séparateur en plein dans le champ d'indice.
Le premier pas

Figure 4: voilà, c'est fait, le return est en place
(ironiquement, c'est maintenant le point de non-retour)
Félicitations: vous venez de faire un petit pas pour vous, mais un pas de géant dans votre base de données. Ce séparateur va vous permettre de rentrer plus d'une donnée dans un seul champ. Est-ce que vous réalisez seulement ce que vous venez de faire?
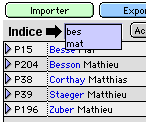 Figure 5a: continuez à taper, sur votre lancée, plusieurs indices: on trouve les "bes" ou les "mat", en même temps. |
 Figure 5b: rappelons que pour trouver les "bes" et les "mat" en même temps, vous pouvez acoller des triplets de lettres. |
Soudain, comme le montre la figure 5a, tout s'éclaire: l'indice est magnanime, et comme l'index l'est aussi, on obtient une magnifique liaison many-to-many. L'indice vous autorise à y déverser tout ce que vous voudrez, pourvu qu'il y ait des returns entre les valeurs. Jouez un peu avec cela. Cela vous permet de trouver plusieurs fiches répondant à plusieurs critères, et ceci simultanément. Nous remplaçons donc, ni plus ni moins, les fastidieuses et peu visuelles commandes "Nouvelle requête" (dans le menu "Requêtes" alors que l'utilisateur se croit en mode "Recherche", et se retrouve un peu dérouté), par de simples... returns!
Savez-vous marcher?
Nous avons dit, à la fin de notre premier article, que les fiches n'étaient vraiment atteignables directement que par leur identifiant, leur numéro, si vous voulez. Un peu comme les voitures, les téléphones, les produits de consommation, les localités, les boîtes aux lettres, les ordinateurs sont atteignables par leurs numéros respectifs (minéralogique, d'appel, codes-barres, NPA, numéro de la rue, adresse TCP/IP), les fiches d'une base de données le sont par leur pk. Les numéros ont ceci d'opportun qu'ils n'ont pas de bornes. On peut en créer autant qu'il nous en faut. Et comme de surcroît ils sont totalement gratuits...
Or notre index est prêt, vous le savez si vous nous avez suivis, à recevoir de telles données numériques. Voyez plutôt:

Figure 5: beaucoup d'indices: on trouve exclusivement les fiches voulues,
car chaque numéro est un identifiant unique
N'est-ce pas merveilleux?
Êtes-vous capable de gambader?
Vous aurez remarqué la présence dans nos deux fichiers Recherche rapide et Navigation d'une série de boutons (si le vôtre ne les possède pas, téléchargez-le à nouveau):
![]()
Figure 6: les trois boutons de nos fichiers d'exemple.
Si vous avez voulu tester nos routines, vous aurez certainement déjà utilisé les deux premiers. Le second, Importer, crée des fiches avec les valeurs de nom et prénom que vous voudrez, les identifiants étant créés lors de l'import même. Exporter fait exactement l'inverse: il ne crache que des identifiants, tout nus, sans autre champ.
Jouons à exporter des fiches, donc. Commençons par exporter quelques résultats de recherches, à titre d'illustration:
- les personnes ayant moins de 22 ans. Nous en trouvons 49. Exportons. Un fichier tabulé est créé.
- les personnes de 22 à 25 ans. Nous en trouvons 83. Exportons. Un fichier tabulé est créé.
- les personnes de 26 à 30 ans. Nous en trouvons 73. Exportons. Un fichier tabulé est créé.
Nous pouvons dès lors ouvrir ces fichiers texte, en copier le contenu, puis le coller... dans l'indice, mais oui! Vous voyez que vous commencez à comprendre!
Figure 7: 49 identifiants, on les copie... |
 Figure 8: ... on colle et on tabule, coucou, les voilà! |
On a dès lors un moyen simple et précis de sortir tout groupe de fiches, pour les stocker quelque part et les réutiliser plus tard (c'est exactement comme une Sélection, si on veut bien, sauf qu'on sort de FileMaker même).
Précisons quelques-uns des immenses avantages des exports d'identifiants:
- Les identifiants n'ont, par définition, aucun sens particulier (est-ce que votre numéro de plaque minéralogique indique aussi que vous avez une Opel bleue? Non, et tant mieux si vous voulez changer de voiture!) On dit en anglais "A primary key has to be meaningless". Dès lors, ils sont d'une sécurité intrinsèque très forte: il est nécessaire de posséder aussi le fichier d'où provient l'export pour qu'il prenne tout son sens en permettant d'atteindre les données elles-mêmes. On peut donc les transmettre sans prendre d'énormes risques.
- Les exports sont très compacts.
- Ils sont figés. Si une fiche venait à disparaître de votre fichier, vous pourriez facilement retrouver laquelle. De même qu'une photographie conserve l'image de vos ancêtres, un export garde une trace indélébile d'une fiche. Et, lorsque la fiche même disparaît, le numéro reste dans l'export. Les photos de vos aïeux ne se sont pas effacées toutes seules à la fin de leur existence, et c'est bien ainsi. Dans le cas contraire, il ne subsisterait plus rien de fiable ni de concret de leur passage en ce monde.
Que diriez-vous de courir?
De mieux en mieux, on sent bien, avec ces fichiers de texte tabulé, que le mode recherche est définitivement relégué aux recherches fines et complexe (il reste indispensable, mais plus pour les recherches simples, répétitives et prévisibles). Mais... à force de tout exporter, est-ce qu'on ne va pas finir par ne plus s'y retrouver une fois de plus? Autrement dit, comment gérer des dizaines, voire des centaines de groupes de fiches?
Un moyen élégant et visuel est d'en faire un tableau... Excel!
![]()
Figure 9: un self-service de recherches prémâchées.
Avec cette astuce, vous pourrez très facilement mettre dans un tableau très parlant toutes les listes fréquemment utilisées, chacune dans une colonne, un peu comme une palette de recherches à votre disposition. De plus, vous pourrez clairement les intituler, de manière que chacun sache exactement sur quelles fiches il va déboucher en copiant-collant ces colonnes dans l'indice du fichier (exemple: dans telle colonne, les Fournisseurs, dans telle autre, les Etudiants, selon les catégories de fiches de votre propre base de données).
Un petit saut périlleux pour les acrobates!
Vous aurez sans doute une dernière question: s'il est très facile de retrouver des fiches depuis une des colonnes de la feuille Excel par simple copier-coller, comment faire si nous désirions, par exemple, trouver les fiches des gens entre 0 et 30 ans (donc ceux qui figurent dans les trois premières colonnes du tableau dans notre exemple)?
Eh bien, notre système d'indice, une fois encore, est prêt pour encaisser ce genre de demande!
Figure 10: on copie les trois premières colonnes... |
 Figure 11: on colle le tout en vrac, et hop! voilà les 205 fiches (49+83+73) qui rappliquent! |
Ainsi, nous tirons profit de la lisibilité d'une table Excel, en laissant les utilisateurs choisir quels groupes ils souhaitent retrouver, avec la possibilité d'additionner les groupes en sélectionnant plusieurs colonnes à la fois.
Ajoutons ce dernier chiffre: un tableau Excel en police de corps 9, sur un écran de 17 pouces, peut aisément afficher 60 lignes et 30 colonnes de pk, soit 1800 données. Ce n'est pas si mal, si l'on y songe. La densité de l'information lui permet d'être clairement visualisée, et basculée dans FileMaker (voir chez Amazon.com les excellents ouvrages d'Edward R. Tufte sur la visualisation de l'information).
Un dernier triple salchow...
En guise de cerise sur le gâteau, nous pouvons vous donner les moyens d'aller encore plus loin. Récapitulons:
- Tout a commencé par la recherche facilitée d'une fiche (indice, à la main).
- Puis de quelques-unes (toujours manuellement), avec des returns entre chacune.
- Puis de beaucoup de fiches, dans des fichiers relativement simples (par copier-coller d'exports tabulés).
- Puis, avec l'aide d'Excel, de beaucoup de groupes de beaucoup de fiches, avec en plus la possibilité de les combiner entre eux.
- Pour les cas extrêmement complexes, devant permettre la représentation de beaucoup de groupes de beaucoup de fiches pour beaucoup d'utilisateurs simultanément, nous ne pouvons que vous conseiller notre routine de Sélections, qui fera merveille. Tout utilisateur pourra mémoriser tout ce qu'il lui faut (se créant par là même, si l'on veut bien, ses propres "sous-fichiers"), le partager ou non avec d'autres utilisateurs, jusqu'à plus de 10000 fiches par sélection (la limite technique actuelle étant les 64000 caractères au maximum dans les champs Texte de FileMaker, ne choisissez donc pas d'identifiants exagérément longs).
Vous en conviendrez, il y a de quoi voir venir!
Pour résumer, nous disposons désormais, en combinant les indices, les index, les exports d'identifiants, les tableaux Excel, les Sélections, de tout un arsenal polyvalent et adapté pour mémoriser des informations sur n'importe quelle combinaison de fiches d'une base de données, et les retrouver en deux clics, pas un de plus, par la suite.
Un quadruple axel carpé avec demi-vrille pour la route...
L'indice peut servir à une dernière chose: le filtrage de doublons.
Supposons que vous disposiez d'un autre fichier, lié à celui qui sert à notre démonstration (par exemple un fichier d'interventions si vous êtes dentiste, lié au fichier de clients). Supposons encore que dans ce fichier lié, vous ayiez une certaine quantité de fiches trouvées, dont vous deviez trouver les clients correspondants. Or certains clients ont subi deux interventions, d'autres trois, quelques-uns quatre... Depuis le fichier d'interventions, il suffit d'exporter les codes des clients en vrac dans un fichier tabulé (les fk dans ce cas, ou Foreign Key, ou clé étrangère dans notre jargon, puisque ce sont des clés liées aux clés pk, qui ne s'appellent ainsi que dans le fichier où elles sont définies), puis de les copier-coller toutes, en vrac, dans le champ d'indice. L'index vous trouvera une et une seule occurrence par clé unique figurant dans l'indice, vous permettant instantanément de reconstituer le groupe des clients concernés par les susdites interventions.
Ce peignage automatisé de valeurs se révèle précieux, très efficace à l'utilisation. FileMaker ne permettant pas l'export d'un index (ce qui est d'autant plus fâcheux que l'index est systématiquement affiché pour l'ensemble des fiches du fichiers, pas seulement celles de la sélection courante), notre routine d'indexation introduit un avantage supplémentaire: un index sur mesure.
Adoptez-les!
Si vous désirez tirer profit de ce qui est présenté ici, il suffit de m'écrire à MathieuBesson@mac.com pour me demander de vous envoyer le mot de passe administrateur de Recherche rapide ou Navigation, afin de pouvoir inclure ces routines à vos développements personnels. Elles ne sont pas onéreuses (15 ou 20 Euros chacune, Navigation comprenant d'ailleurs Recherche Rapide), mais elle pourraient vous faire gagner beaucoup, beaucoup de temps de travail.