
Plusieurs méthodes, plus ou moins compliquées, plus ou moins astucieuses,
avec différents avantages, pour gérer les numéros postaux de localités.
Nous détaillons ici quatre approches pour afficher des données liées: par des menus déroulants, des listes, des tables externes et finalement une polyvalente palette flottante. Vous pouvez télécharger cette palette pour Mac et pour PC; nous proposons les deux compressions, bien que les PéCéistes possèdent aussi StuffItExpander.
Tout utilisateur de FileMaker a un jour créé un fichier d'adresses. Beaucoup auront alors à cette occasion créé leurs premiers menus, affichés leurs premiers index (la liste de toutes les localités existantes dans le fichier), puis enfin tiré leurs premiers liens entre fichiers relationnels, en essayant d'améliorer la saisie de ces deux rubriques intimement liées (le NPA et le nom correspondant d'une localité) en les regroupant par convenance au sein d'un fichier indépendant.
Les objectifs sont les suivants, par ordre décroissant d'importance:
- éviter les erreurs de saisie.
- gagner du temps en apportant une aide à l'utilisateur qui retape fréquemment les mêmes mots, et qui finit par en avoir assez.
- permettre une recherche rapide si une des deux informations vient à manquer.
Le principal problème, c'est qu'il n'existe pas toujours un numéro postal pour une et une seule localité: on devra fréquemment proposer une liste de choix à l'utilisateur, ou lui glisser la solution la plus probable:
- Il y a plusieurs Lully, Aesch, Au, Buchs, Kirchberg, Saint-Martin, Romont, avec des NPA différents.
- Inversement, la poste suisse regroupe fréquemment plusieurs localités sous le même numéro (un office pour plusieurs communes). 1041 correspond à pas moins de... 13 communes: Bettens, Bottens, Boulens, Bretigny-sur-Morrens, Dommartin, Echallens Sorties, Montaubin-Chardonney, Naz, Oulens-sous-Echallens, Peyres-Possens, Poliez-le-Grand, Poliez-Pittet et Saint-Barthélémy.
- Les grandes villes ont parfois plusieurs dizaines de numéros avec des appellations légèrement différentes.
- Il y a fréquemment des noms de localité à coucher dehors, surtout si l'on pense aux communes d'origine.
On se rend compte que dans tous les cas, il est utile de prendre le temps de réfléchir à ce problème. C'est le seul moyen de ne pas devoir un jour nettoyer des milliers de fiches truffées de fautes imprévues.
Méthode 1A: on entre le NPA, et un menu propose la ou les localités correspondantes
C'est l'approche la plus commune. Entre le fichier d'adresses et le fichier de NPA, on tire un lien sur les deux rubriques de NPA. On crée ensuite dans le fichier d'adresses une liste de valeurs qui contient uniquement les localités liées.
Il suffit dès lors de taper un nombre à quatre chiffres, et la liste des localités correspondantes est affichée dans un menu.
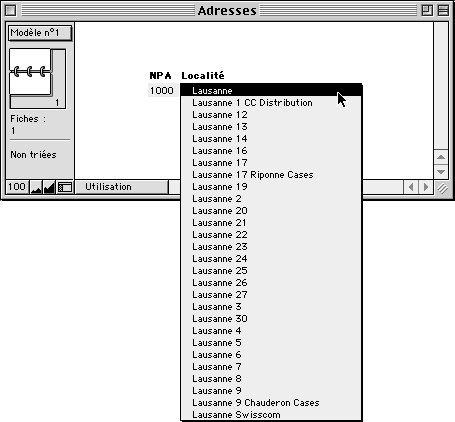
Méthode 1A: menu de Localités
Pas mal. Peut-on faire mieux?
Méthode 1B: on entre la localité, et un menu propose le ou les NPA correspondants
Certains préfèrent l'inverse. Entre le fichier d'adresses et le fichier de NPA, on tire un lien sur les deux rubriques de Localité. On crée ensuite dans le fichier d'adresses une liste de valeurs qui contient uniquement les NPA liés.

Méthode 1B: menu de NPA
Note:
En plus du menu, on peut aussi choisir d'activer l'entrée automatique de la rubrique à menu, pour les nombreux cas où un NPA correspond à une localité: cela permet d'éviter que le menu reste vide si l'on oublie de le cliquer, il contiendra au moins une valeur par défaut.
Avantages:
- On a toutes les valeurs à portée de clic.
- On empêche l'utilisateur de taper n'importe quoi dans le champ à menu.
Inconvénients:
- On doit choisir une des deux méthodes: un des deux champs doit permettre la saisie, et l'autre est bloqué par un menu.
- C'est simple pour un utilisateur, mais c'est ennuyeux pour travailler en groupe: parfois on connaît le NPA, parfois la ville. Parfois encore, on n'est pas certain ni du chiffre, ni de l'orthographe, et on aimerait bien pouvoir chercher.
Très bien, nous progressons. Peut-on faire encore mieux?
Méthode 2: On propose deux listes pour les deux champs.
On garde les deux liens que l'on a créé précédemment pour les méthodes 1A et 1B, et on utilise les deux listes de valeurs sur deux listes déroulantes. Les deux rubriques autorisent dès lors la saisie, et engendrent une liste de suggestions pour l'autre champ.
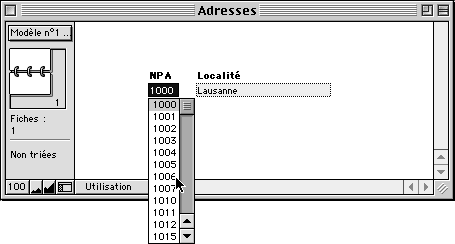 Une liste de NPA si l'on tape un nom de localité. |
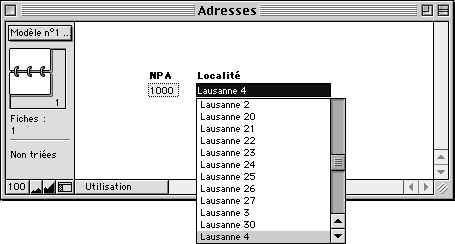 ... en même temps qu'une liste de localités si l'on rentre un NPA. |
Note:
On ne peut pas activer d'entrée automatique pour les deux rubriques simultanément, sinon on provoque une référence circulaire. Donc, en réalité, on doit quand même faire un choix de priorité: une rubrique prime sur l'autre.
Avantages:
- On donne des indices pour les deux champs.
- On laisse l'utilisateur donner les deux informations dans l'ordre qu'il préfère.
Inconvénients:
- On perd toute certitude que l'utilisateur respectera les valeurs qui figurent dans les listes. C'est très ennuyeux, on accorde trop de liberté à l'utilisateur, on perd un peu de contrôle.
- Plus ennuyeux encore: si la valeur exacte n'existe pas dans le fichier des NPA, le menu réciproque reste... blanc!
 Si on se trompe, le menu reste vide. |
 Pas très parlant, vous ne trouvez pas? |
On croyait avoir mis la main sur une méthode conciliant les avantages des deux premières, mais on débouche sur un gros risque de données incorrectes, si les données que l'on rentre sont imprécises...
Damned, FileMaker n'aurait-il donc rien de mieux à proposer? Une application aussi évoluée ne pourrait-elle aider l'utilisateur à retrouver son chemin? Le développeur va devoir faire un petit effort, voyons comment...
Méthode 3: utilisons une table externe, avec quelques rubriques astucieusement calculées.
On peut prendre le problème autrement: donner en tout temps un moyen simple et rapide pour que l'utilisateur puisse rechercher la bonne information. Une fois qu'il l'aura trouvée, il n'aura plus qu'à glisser le NPA correct dans le bon champ, et le tour sera joué. Le contrôle sera complet, et la liberté de l'utilisateur encore plus étendue que dans les méthodes précédentes.
Le but de cette astuce est de fournir le moyen à l'utilisateur de ne spécifier que des bribes d'information s'il n'a pas l'information complète à disposition. Par exemple, ce sera utile si l'utilisateur ne se souvient que du début du NPA, ou s'il n'est pas certain de l'orthographe de la localité.
Pour ceci, il faut créer deux nouvelles rubriques:
- une dans le fichier d'Adresses: g_npa_indice, une rubrique globale de type texte, pour taper un indice (numéro ou texte)
- une dans le fichier de NPA: c_localite_debut, un calcul, qui contient quatre fragments croissants de NPA (premier chiffre, deux premiers chiffres, trois premiers chiffres, NPA entier) et vingt fragments croissants de Localité (même principe, jusqu'à 20 caractères, puisque FileMaker n'indexe de toute façon que les 20 premiers caractères des mots).
... et de tirer un lien entre ces deux rubriques g_npa_indice et c_localite_debut. On peut ainsi créer une table externe dans le fichier d'adresses pour afficher une sélection de NPA et de localités, en fonction d'un paramètre temporaire (le champ global).
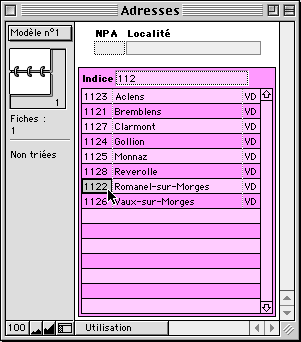 On tape une partie du NPA... |
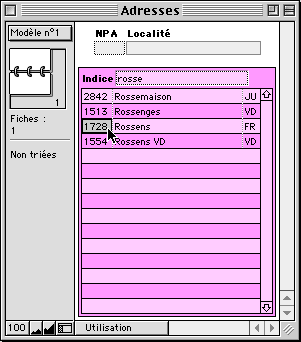 ... ou quelques lettres du nom recherché... |
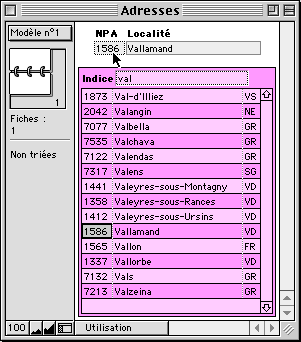 ... il suffit de drag-n-dropper le numéro adéquat dans la rubrique du fichier, et le tour est joué. |
Avantages:
- On est certain que la valeur sera correcte.
- Le contrôle du contenu des champs est excellent.
- La liberté de l'utilisateur encore plus étendue que dans les méthodes précédentes: en utilisant une variable globale pour donner l'indice, l'utilisateur se sent un peu chez lui: il tape ce qu'il veut, jusqu'à ce qu'il trouve ce qu'il cherche.
Inconvénients:
- On doit prévoir exactement à quel endroit l'utilisateur aura besoin de rechercher une information de localité ou de NPA, et modifier le modèle en conséquence en incorporant une table externe affichant le fichier NPA.
- Ça prend pas mal de place, et la plupart du temps, cette table externe restera vide et inutile.
Existerait-t-il une solution encore plus polyvalente?
Méthode 4: une palette de NPA!
En reprenant exactement le même principe que ci-dessus, on se crée une palette flottante qui ne sert qu'à rechercher rapidement des NPA ou des localités. On ne travaille que dans le fichier de NPA.
Concrètement, il faut avoir à disposition les deux mêmes rubriques g_npa_indice et c_localite_debut, mais toute l'astuce consiste à les créer au sein du même fichier, le fichier de NPA. De là, on se crée encore:
- Un lien de g_npa_indice à c_localite_debut, donc de NPA vers NPA (rien n'interdit FileMaker de faire du relationnel... à un seul fichier!)
- un modèle contenant une table externe sur les fiches liées (une sorte de "table interne", si l'on veut bien, puisque le fichier se regarde lui-même à travers un lien, un peu comme un dentiste qui se détartrerait en se regardant dans un miroir).
 On peut toujours glisser-déposer d'un fichier à l'autre. |
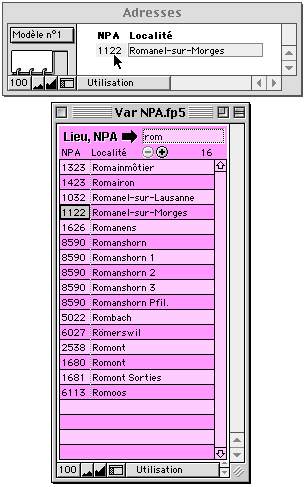 On a donc partout ses NPA sous la main. |
Téléchargez cette palette pour Mac et pour PC. Vous pouvez l'utiliser en freeware, ou l'acheter 10 francs suisses si vous désirez l'incorporer à vos fichiers. Ecrivez-moi pour me demander le code d'accès.
Avantages:
- On est certain que la valeur sera correcte.
- Le contrôle du contenu des champs est excellent.
- La liberté de l'utilisateur encore plus étendue que dans les méthodes précédentes: en utilisant une variable globale pour donner l'indice, l'utilisateur se sent un peu chez lui: il tape ce qu'il veut, jusqu'à ce qu'il trouve ce qu'il cherche.
- Le fichier NPA transformé de la sorte est devenu totalement indépendant du reste de la solution de bases de données relationnelles, tout en restant aussi un fichier de données lorsqu'on en a besoin (pour générer des menus ou des listes, par exemple).
- On n'a plus besoin de savoir où l'utilisateur aura envie ou besoin de chercher l'information de Localité ou de NPA.
- Si la table externe est souvent vide, elle est aussi très souvent cachée, puisque c'est une palette. On peut même la minimiser dans le dock ou en barre de titre, pour la faire surgir au besoin.
Inconvénient:
- Plus complexe à conceptualiser et à mettre en oeuvre. Mais c'est bien le travail d'un développeur, non?
Conclusion
Il nous semble que cet exemple montre à merveille que l'effort du développeur en vaut très largement la peine pour l'utilisateur. Voire pour le développeur qui sommeille en vous également, puisque le fichier obtenu est un peu une base de données "objet", un module réutilisable partout où vous aurez besoin de numéros postaux. Il est intéressant de regrouper au sein du même fichier les modèles et tables qui seront requises quelque part dans votre solution: si vous développez un fichier de cette manière, vous pourrez simplement le remplacer dans toutes les solutions que vous programmez en deux coups de cuillère à pot, sans devoir modifier le moindre modèle dans les fichiers liés.
On constate aussi un louable retour au premier plan d'un fichier (ici NPA), qui, à l'instar de nombreux fichiers satellites dans une grosse solution relationnelle, était passé au second plan dans une évolution typique de base de données personnelle:
- On part d'un fichier simple (typiquement des adresses).
- On regroupe, on éloigne, certaines rubriques dans un fichier spécifique (ici les correspondances NPA-Localités).
- On se retrouve finalement un peu encombré par ce nouveau fichier, qui ne sert que de dépôt de données.
- On est parfois obligé de protéger ce fichier satellite, de manière que l'utilisateur ne puisse jamais contourner les menus et automatismes mis en place dans le fichier principal (en allant par exemple modifier un canton, ou rajouter des appellations de lieux-dit non officiels).
- On redonne une utilité intrinsèque à ce fichier en le dotant d'un modèle contenant une table externe sur lui-même.
Le même principe peut être appliqué pour nombre d'autres fichiers.
Mathieu Besson